CockroachDB 2.0 has just been released. For those who don’t know what it is, it can be summarized as a SQL database for the cloud era. One of the best things about CockroachDB is that it automatically scales, rebalances and repairs itself without sacrificing the SQL language. Moreover, Cockroach implements ACID transactions, so your data is always in a known state.
In this post, I am going to explain how to install it in Kubernetes/OpenShift, insert some data and validate that it has been replicated in all nodes. In next post, I am going to show you how to use it with Spring Boot + JPA.
The first thing you need to have is a Kubernetes/OpenShift cluster to be used. You can use Minikube or Minishift for this purpose. In my case, I am using Minishift but I will provide equivalent commands for Minikube.
After having everything installed, you need to launch the Cockroach cluster.
In case of Kubernetes:
kubectl create -f https://raw.githubusercontent.com/cockroachdb/cockroach/master/cloud/kubernetes/cockroachdb-statefulset.yaml
In case of OpenShift:
oc apply -f https://raw.githubusercontent.com/cockroachdb/cockroach/master/cloud/kubernetes/cockroachdb-statefulset.yaml
Then you need to initialize the cluster:
In case of Kubernetes:
kubectl create -f https://raw.githubusercontent.com/cockroachdb/cockroach/master/cloud/kubernetes/cluster-init.yaml
In case of OpenShift:
oc apply -f https://raw.githubusercontent.com/cockroachdb/cockroach/master/cloud/kubernetes/cluster-init.yaml
Then let’s configure the cluster so we can access the admin UI:
In case of Kubernetes:
kubectl port-forward cockroachdb-0 8080
In case of OpenShift:
oc expose svc cockroachdb-public --port=8080 --name=r1
Now let’s create a database and a table and see how it is replicated across all the cluster easily.
Cockroach comes with a service that offers a load-balanced virtual IP for clients to access the database.
In case of Kubernetes:
kubectl run cockroachdb -it --image=cockroachdb/cockroach --rm --restart=Never -- sql --insecure --host=cockroachdb-public
In case of OpenShift:
oc run cockroachdb -it --image=cockroachdb/cockroach --rm --restart=Never -- sql --insecure --host=cockroachdb-public
And finally in the opened console just type some SQL calls:
create database games; use games; create table game (id int, title varchar(30)); insert into game values (1, 'The Secret of Monkey Island');
So far, we have a new database, table, and entry in CockroachDB. Open admin UI, push Databases and you’ll see something like this:

You can see that the database and the table have been created. Now let’s see how we can know that everything has been replicated correctly. Push Overview and you’ll see something like:
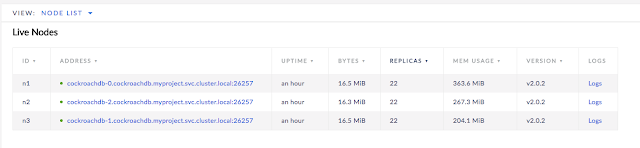
So pay attention to Replicas column. In all nodes, the number is exactly the same number, this means that all data in the cluster has been replicated X times.
Now let’s increase by one the number of replicas and just refresh the page to see that the new node initially has not the same replica count.
In case of Kubernetes:
kubectl scale statefulset cockroachdb --replicas=4
In case of OpenShift:
oc scale statefulset cockroachdb --replicas=4
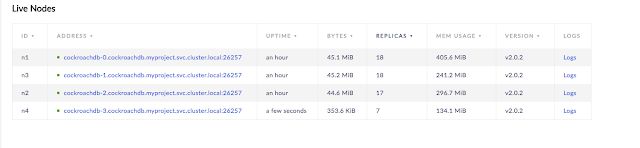
Another thing you can do is to just enter each container and validate that when connecting to localhost, the inserted data is there.
In case of Kubernetes:
kubectl exec -it cockroachdb-0 /bin/bash
In case of OpenShift:
oc exec -it cockroachdb-0 /bin/bash
Then inside the container just run:
./cockroach dump games --insecure
And you will see that CLI connects by default to the current node (localhost) and dumps the content of games db.
Repeat the same with other nodes cockroachdb-1 and cockroachdb-2 and you should see exactly the same.
So as you can see, it is really easy to use SQL in scale way thanks to Cockroach DB. In next post, we are going to see how to integrate Spring Boot + JPA with Cockroach DB, and deploying it into Kubernetes.
We keep learning,
Alex
| Published on System Code Geeks with permission by Alex Soto, partner at our SCG program. See the original article here: CockroachDB. A cloud native SQL database in Kubernetes. Opinions expressed by System Code Geeks contributors are their own. |
