We are living the era of buzzwords, and Docker is for sure one of those in the technological landscape. Docker has a common sense definition: hypervisor-free virtualization.
In other terms: running VMs without any hypervisor-based virtualization support. Now, how is this possible? What is the arcane trick to achieving that?
Let’s live a short journey to sketch the context out, and to assess the enabling technologies underneath Docker which enable dense virtualization.
Where the Journey Begins…
Kernel-level virtualization has been addressed since mid 2000s, and one of the well-known technologies from that time is KVM (standing for for Kernel-based Virtual Machine). In parallel to this public effort, led by RedHat, Linux Containers were under development and the idea was to combining the Cgroups capabilities with namespaces; Engineers like Paul Menage and Rohit Seth were leading the effort to develop the Cgroups support into the Linux Kernel to provide resource limitations to OS-level processes (e.g. CPU, RAM, and I/O) separated in the scope and contexts.
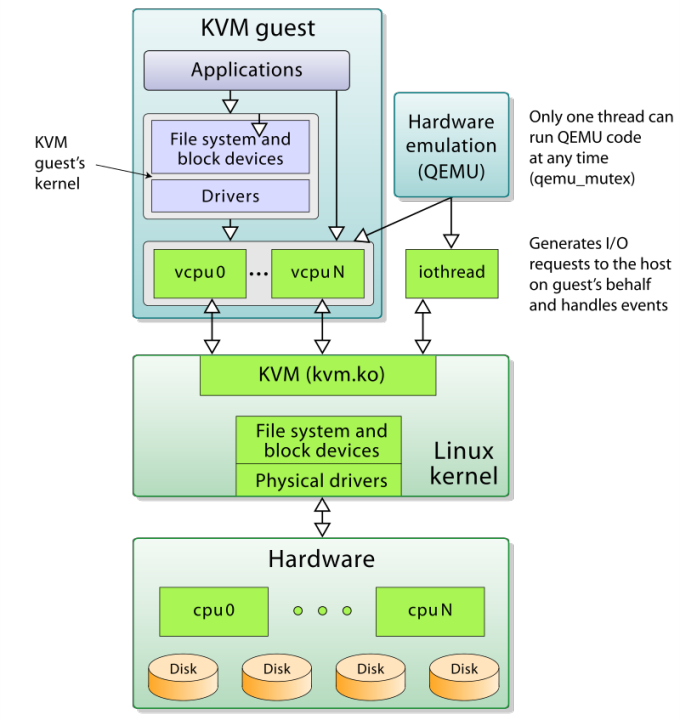
KVM resulted in a different design, if compared to Linux Containers. The effort was concentrated in realizing a Kernel-level Hypervisor technology able to provide a fast virtualization support natively in the Kernel, using the CPU virtualization extensions. In the below picture, the fundamentals of KVM design.
Linux Containers, on the other hands, staying within the Kernel-level virtualization design, adopted a different paradigm: sharing the Kernel itself among host and guest instances, so no longer a module of the Kernel aiding at virtualizing, but the Kernel itself acts as shared resource manager. This concept will be clear in a moment, when the techniques will be compared – stay tuned.
Since mid 2000s, both the techniques have matured, and recently Linux Containers have gained more notoriety thanks to Container Engines like Docker facilitating the usage of LXC user space APIs.
Hypervisor: Who is it?
Virtualization can be intended as para-virtualization, or full-virtualization. The first approach consists in a set of APIs provided by the host to the guest that allows to facilitate tasks from a guest OS perspective; guest OSs should support the para-APIs to request a specific set of resources directly to the host OS, bypassing the virtualization layers.
The second approach, instead, consists in virtualizing completely the underlying hardware (i.e. whatever is related to CPU, RAM, I/O and connected devices via the system bus), providing an isolated execution sandbox for the guest OS; with this approach, the guest OS is not even aware about its status: running in a virtual machine, created by the virtualization layer and precisely mirroring the behavior of the underlying physical machine.
Virtual Machines Monitor (VMM) are basically the Hypervisors that enable the virtualization as above defined. VMMs can be implemented in i. software, ii. firmware or even iii. hardware, and according to their implementation can be classified as native or bare-metal hypervisors, or hosted hypervisors.
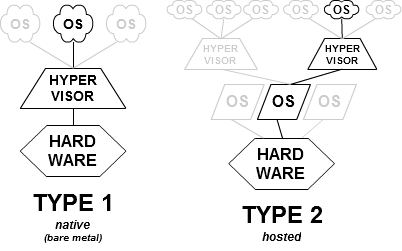
The aim of an Hypervisor is: disciplinate the guest OSs in a way the their requests can be multiplexed on physical hardware, trying to take the maximum benefit from the bare-metal hardware capacity – often Applications as well as hosting OSs are not able to use close to 100% of the hardware resources. In other terms: increasing the density (how many guest OSs per bare-metal hardware) to avoid any waste of the physical computational resources.
Summing up, an Hypervisor normally emulates a physical machine, and creates a sandbox environment to run an instance of guest OS (modified, or not according to the virtualization paradigm).
LXC-based Virtualization
As said, an Hypervisor provides an emulated secure box in which a guest OS can be run; the guest OS is installed in all its parts (Kernel comprised) into the secure and isolated box.
LXC-based virtualization uses the Linux Containers, a completely different form of Kernel-based virtualization. The host OS shares the Kernel with guest OSs, and in terms of execution environment a VM resembles to an hierarchy of OS processes, disciplined in terms of resources utilization, and securely isolated in terms of contexts.
Cgroups kernel modules is able to create a resource utilization virtualization and discipline to the guest OS; instead, kernel namespaces isolated the hierarchy of processes from all the others running and managed by the shared kernel. Below picture tries to give an idea of how a guest OS looks like from a LXC perspective.
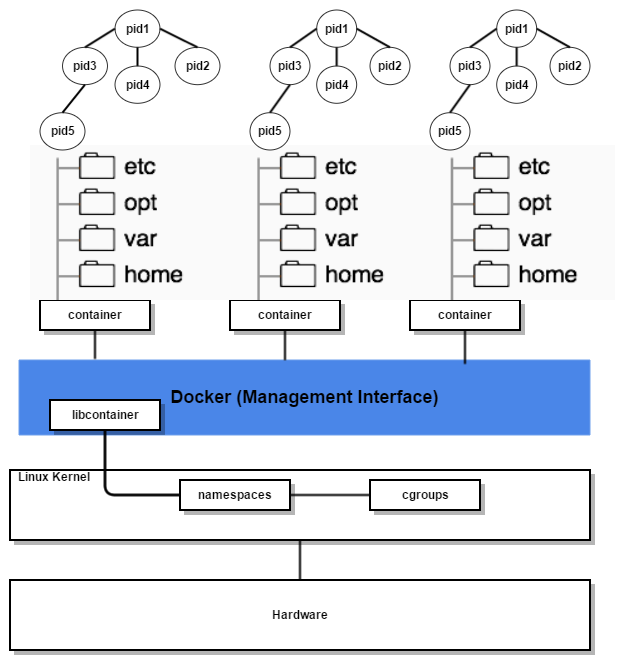
Each guest OS will get its own PID1, that looking from the outside is a child process of the host OS (that has its own PID1). Moreover, each Container will get its own file system realized as a set of folders accessible from the host OS, but not from any other guest OS running on the same Kernel. These are two key concepts: PIDs as well as file systems and bridged network devices are accessible and manageable from the outside world (i.e. host OS), but not from any other Container running in parallel on the same Kernel.
In a simplistic way, a Container can be seen as an isolated set of processes, interacting with an isolated set of folders and device networks (as above depicted). A completely different approach: there is no machine emulation, instead there is a resource demultiplexing operated by the host OS itself, with a set of clear advantages in terms of effectiveness and speed.
The role of Docker in such kind of virtualization consists in wrapping the low-level user space Kernel API into a more semantically powerful set of high-level API to spin up Containers, and to seamlessly working with OS images to be used to create new instances of host OS Containers.
Hypervisor- Vs LXC-based Virtualization
Let’s start with a picture that can be worth-a-thousand-words.
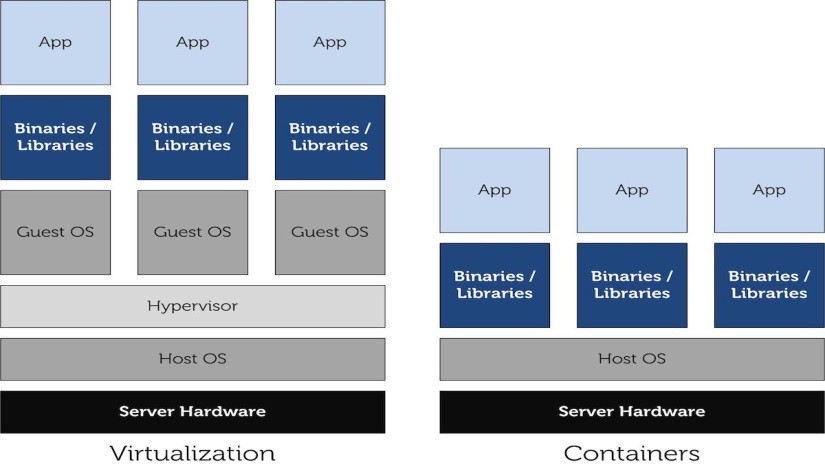
A containerized guest OS is simply a set of libraries and binaries specific of that operating system which is supposed to use a common and compatible Kernel version; isolated hierarchy of system processes, file system, devices allow those binaries and libraries to run seamlessly on the host Kernel without interfering with all other containers and, more important, with the host tasks.
To stress the difference, the host Kernel is shared among the Containers, with Hypervisor-based virtualization each VM has its own Kernel. This aspect is a key factor: with Containers only OSs supposedly using the same Kernel can be spun up: e.g. a Linux host cannot run a containerized Windows OS, because Windows OSs make use of their own proprietary Kernel, which is for sure a non Linux-derived one. Therefore, OSs using Kernels different from Linux Kernel cannot be run into Containers, they can instead run into KVM VMs: QEMU is able to run Windows on Linux boxes, via KVM virtualization and dynamic translation.
As intuitive, any LXC Container is much more lightweight than a VM, and this is an important factor in terms of speed: Containers’ processes execute canonical system call to get access to hardware resources, instead VMs’ processes execute local (to the sandbox) calls that address virtual hardware and in turn are translated into canonical system calls. The flow is clear: a Container acts natively, instead a VM interacts with a heavyweight wrapping layer with many level of indirection to abstract the physical hardware in emulated resources.
LXC Containers are faster than VMs, in terms of: installation, bootstrapping and single operation. Any automated deploy of a LXC Container, reduces the times from minutes to a very few seconds. To be convinced, let’s compare the two cases:
- Spinning Up an Ubuntu Container.
- Download the Container Image (few megabytes).
- Creating the Container (few seconds).
- Bootstrapping (immediate).
- Spinning Up an Ubuntu VM.
- Download the Distro Image (few gigabytes).
- Creating the VM (few minutes).
- Installing the Distro into the VM (few minutes to an hour).
- Bootstrapping (few seconds).
For a Container, step 2 and 3 of the VM case are merged in the only step 2: creating a Container means parsing the image and deploying the resources according to the the specific Distro targeted by the description file. Even if both the Container and VM are ready to use (no download and installation creation), the startup time is not even comparable: a Container bootstraps immediately cause it consists of an OS process with a few child processes (defined by the guest services specified into the Container description file), instead a VM requires few seconds to bootstrap cause the overall OS has to be initialized and daemon services have to be started.
Elastic Scalability
Clearly, with reduced startup times, Containers are ideal for elastic scale out scenarios: services are reactively replicated according to the demand. Often, such scenarios are labeled as Elastic Cloud Computing, technical layers adapt according to the workload to satisfy the increasing/decreasing demand using effectively the computation resources (i.e. scaling the adaptively cost down and up, having an overall gain over time).
Virtualization Density
Side by side, VMs and Containers have different footprints and so computing needs. A VM is much heavier and demands a relevant work to the host OS: for instance, process context switch has to be properly translated for the underlying OS that, in the easiest case, deals with a bunch of VM processes. As said, a Container is much lighter and demands far less work to the host OS: processes are native, no translation is needed, they are scheduled according the Cgroups and namespaces policies and priorities.
As clear, LXC can multiplex hardware resources to a number of Containers, and such number is much bigger if compared to the number of VM instances that an Hypervisor can manage on the same hardware; normally, the number of Containers per bare-metal is 2 order of magnitude bigger than the number of VMs.
Spinning Up a VM in few Seconds
Docker is one of the Container Engines out there, popular because versatile and well-designed. It is shipped with a CLI, a layer of APIs and a daemon which manages the Containers’ life cycles.
Assuming that Docker is already installed (for more info, the official documentation can help), the goal is to spinning up an Ubuntu Container. Let’s go through the steps.
Pull/Download the Container Image
$ docker pull ubuntu
Create and Run the Container with an attached shell
$ docker run -i -t --name ubuntu /bin/bash
Downloading the Image from Docker Hub will take a few minutes (it really depends from the connection speed and the size of that Image itself). To create and start the Container will take a few seconds: the detached OS processes is supposed to run a bash shell, so only a fork is needed, apart of the rest of creation steps involving a few other basic processes; and, to be convinced:
$ docker exec ubuntu ps aux
this command displays the process tree running into the instantiated Container, and it looks like:
$ docker exec ubuntu ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 18264 3284 ? Ss+ 16:40 0:00 /bin/bash root 34 0.0 0.0 15572 2092 ? Rs 23:33 0:00 ps aux
As said, the bootstrapping process is very quick (normally, less than a second); below a practical proof of this concept.
$ time docker run -d ubuntu fea3508d69f0ba4ca5cf12b322b4462911e4b8c52f2aeb67cfaf969507732068 real 0m0.634s user 0m0.019s sys 0m0.019s
Conclusion
Linux Containers are a modern technology to achieve dense virtualization and elastic scalability. They are lightweight, fast in bootstrapping and extremely versatile: Containers can be potentially mapped 1 to 1 with Services/Applications. They performs native System Calls, and are isolated each other via Kernel sophisticated mechanisms.
The only disadvantage consists in their own intrinsic limitation: sharing the host Kernel, they are not able to run OSs using non Linux-derived Kernels (as said, Windows OS cannot be containerized because such OS uses a proprietary Kernel which is non Linux-derived).
Container Engines aids by providing managed environment and offering clean APIs to spin up Containers. An example of such Engines is Docker.
Concluding, Containers are an agile mechanism to run guest OSs based on the isolated and protected multiplexing of Kernel resources to such guests. They are ideal for any Elastic Cloud Computing scenario, because they ensure a denser virtualization than Hypervisor-based VMs.
| Reference: | Dense Virtualization via Linux Containers from our SCG partner Paolo Maresca at the TheTechSolo blog. |

Thanks…nice article. Would have been nice to mention that Solaris 10 and 11 have been doing containers for more than 10 years!
We will be supporting Docker: https://www.oracle.com/corporate/pressrelease/docker-gets-in-the-zone-with-oracle-solaris-073015.html
And I avoid referring to containers as “VMs”…that implies a hypervisor. So I say “Virtual Environments (VEs”) to emphasize that
there’s more than one way to virtualize an execution environment…BSD Jails, Solaris Zones (containers), etc.
Harry
Hi Harry! Thanks for your feedback, I really appreciate.
I’m going to fix the terminology: I do agree with you, VEs is better suited to the case.
I’m going to add a note on Solaris too.
Again, thanks a lot!
Paolo