This is an awk tutorial. The basic function of awk is to search files for lines or other text units containing one or more patterns.
When a line matches one of the patterns, special actions are performed on that line. Programs in awk are different from programs in most other languages, because awk programs are “data-driven”. You describe the data you want to work with and then what to do when you find it.

Most other languages are “procedural.” You have to describe, in great detail, every step the program is to take. When working with procedural languages, it is usually much harder to clearly describe the data your program will process.
For this reason, awk programs are often refreshingly easy to read and write.
The following table shows an overview of the whole article:
Table Of Contents
1. Introduction
When you run awk, you specify an awk program that tells awk what to do. The program consists of a series of rules. It may also contain function definitions, loops, conditions and other programming constructs, advanced features that we will ignore for now.
Each rule specifies one pattern to search for and one action to perform upon finding the pattern.
There are several ways to run awk. If the program is short, it is easiest to run it on the command line:
awk PROGRAM inputfile(s)
If multiple changes have to be made, possibly regularly and on multiple files, it is easier to put the awk commands in a script.
This is read like this:
awk -f PROGRAM-FILE inputfile(s)
2. The print Program
2.1 Printing selected fields
The print command in awk outputs selected data from the input file. When awk reads a line of a file, it divides the line in fields based on the specified input field separator, FS, which is an awk variable. This variable is predefined to be one or more spaces or tabs.
The variables $1, $2, $3, …, $N hold the values of the first, second, third until the last field of an input line.
The variable $0 (zero) holds the value of the entire line.
ls -l | awk '{ print $5 $9 }'
In the output of ls -l, there are 9 columns. The print statement uses these fields as follows:
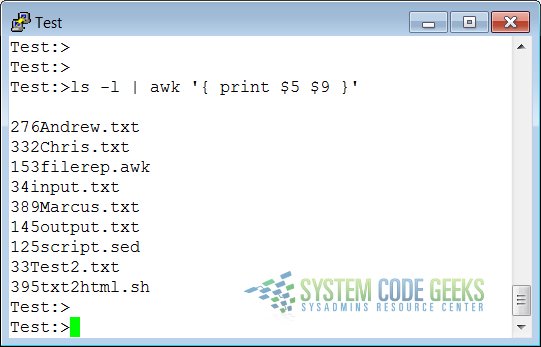
This command printed the fifth column of a long file listing, which contains the file size, and the last column, the name of the file. This output is not very readable unless you use the official way of referring to columns, which is to separate the ones that you want to print with a comma. In that case, the default output separater character, usually a space, will be put in between each output field.
2.2 Formatting fields
Without formatting, using only the output separator, the output looks rather poor. Inserting a couple of tabs and a string to indicate what output this is will make it look a lot better:
ls -ldh * | grep -v total | \
awk '{ print "Size is " $5 " bytes for " $9 }'

Note the use of the backslash, which makes long input continue on the next line without the shell interpreting this as a separate command. While your command line input can be of virtually unlimited length, your monitor is not, and printed paper certainly isn’t.
Using the backslash also allows for copying and pasting of the above lines into a terminal window.
The -h option to ls is used for supplying humanly readable size formats for bigger files. The output of a long listing displaying the total amount of blocks in the directory is given when a directory is the argument.
This line is useless to us, so we add an asterisk. We also add the -d option for the same reason, in case asterisk expands to a directory.
The backslash in this example marks the continuation of a line.
2.3 The print command and regular expressions
A regular expression can be used as a pattern by enclosing it in slashes. The regular expression is then tested against the entire text of each record. The syntax is as follows:
awk 'EXPRESSION { PROGRAM }' file(s)
Below another example where we search the current directory for files ending in “.txt” and starting with either “i” or “o”, using extended regular expressions:
ls -l | awk '/\<(i|o).*\.txt$/ { print $9 }'
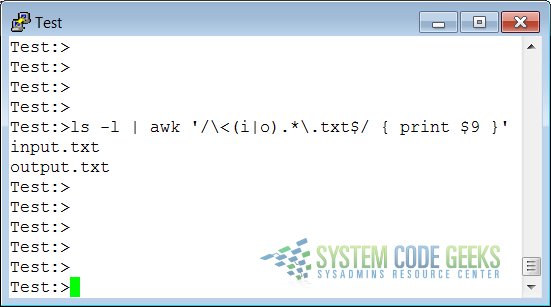
This example illustrates the special meaning of the dot in regular expressions: the first one indicates that we want to search for any character after the first search string, the second is escaped because it is part of a string to find (the end of the file name).
2.4 Special patterns
In order to precede output with comments, use the BEGIN statement:
ls -l | \
awk 'BEGIN { print "Files found:\n" } /\<[a|x].*\.txt$/ { print $9 }'

The END statement can be added for inserting text after the entire input is processed:
ls -l | \
awk '/\<[a|x].*\.txt$/ { print $9 } END { print \
"Can I do anything else for you, mistress?" }'

2.5 awk Scripts
As commands tend to get a little longer, you might want to put them in a script, so they are reusable. An awk script contains awk statements defining patterns and actions.
filerep.awk
BEGIN { print "*** Information ***" }
/\<[a|x].*\.txt$/ { print "File " $9 "\t: " $5 " Bytes!" }
END { print "*** about Textfiles and their size ***" }
The following command executes the script:
ls -l | awk -f filerep.awk
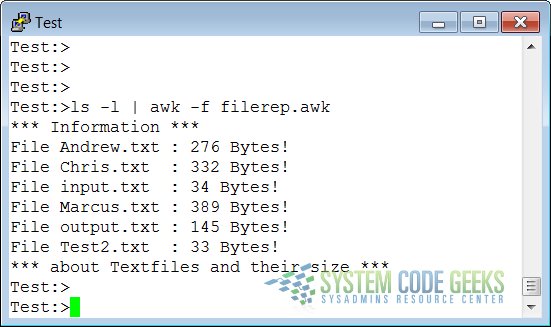
awk first prints a begin message, then formats all the lines that contain an eight or a nine at the beginning of a word, followed by one other number and a percentage sign. An end message is added.
3. awk Variables
As awk is processing the input file, it uses several variables. Some are editable, some are read-only.
3.1 The input field separator
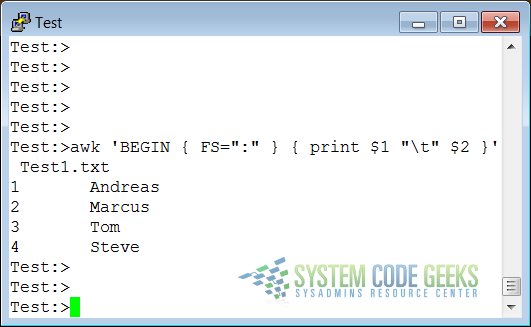
The following file represents a list with the Id and Name of different persons:
Test1.txt
1:Andreas 2:Marcus 3:Tom 4:Steve
The field separator, which is either a single character or a regular expression, controls the way awk splits up an input record into fields. The input record is scanned for character sequences that match the separator definition. The fields themselves are the text between the matches.
The field separator is represented by the built-in variable FS. Note that this is something different from the IFS variable used by POSIX-compliant shells.
The value of the field separator variable can be changed in the awk program with the assignment operator =.
Often the right time to do this is at the beginning of execution before any input has been processed, so that the very first record is read with the proper separator. To do this, use the special BEGIN pattern.
In the example below, we build a command that displays all the users on your system with a description:
3.2 The output separators
Test2.txt
The following file represents a list with the Id and Name of different persons. The separator will be represented by a Tabulator in this case:
1 Andreas 2 Marcus 3 Tom 4 Steve
3.2.1 The output field separator
Fields are normally separated by spaces in the output. This becomes apparent when you use the correct syntax for the print command, where arguments are separated by commas:
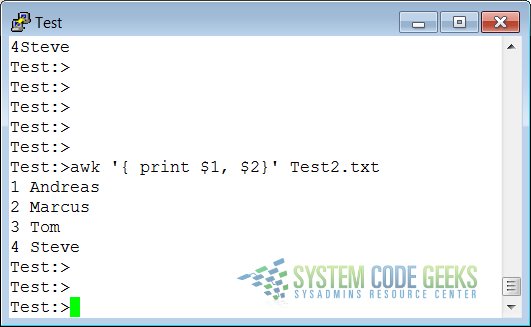
If you don’t put in the commas, print will treat the items to output as one argument, thus omitting the use of the default output separator, OFS.
3.2.2 The output record separator
The output from an entire print statement is called an output record. Each print command results in one output record, and then outputs a string called the output record separator, ORS.
The default value for this variable is “\n”, a newline character. Thus, each print statement generates a separate line.
To change the way output fields and records are separated, assign new values to OFS and ORS:
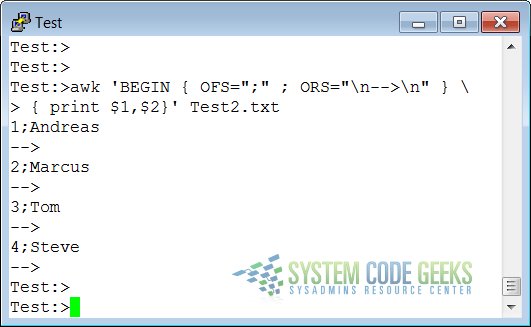
3.3 The number of records
The built-in NR holds the number of records that are processed. It is incremented after reading a new input line. You can use it at the end to count the total number of records, or in each output record:
records.awk
BEGIN { OFS="-" ; ORS="\n--> done\n" }
{ print "Record number " NR ":\t" $1,$2 }
END { print "Number of records processed: " NR }

4. Summary
The awk utility interprets a special-purpose programming language, handling simple data-reformatting jobs with just a few lines of code. It is the free version of the general UNIX awk command.
This tools reads lines of input data and can easily recognize columned output. The print program is the most common for filtering and formatting defined fields.
On-the-fly variable declaration is straightforward and allows for simple calculation of sums, statistics and other operations on the processed input stream. Variables and commands can be put in awk scripts for background processing.
