This article is part of our Academy Course titled PostgreSQL Database Tutorial.
In this course, we provide a compilation of PostgreSQL tutorials that will help you set up and run your own database management system. We cover a wide range of topics, from installation and configuration, to custom commands and datatypes. With our straightforward tutorials, you will be able to get your own projects up and running in minimum time. Check it out here!
In our previous article we discussed how to free up disk space by vacuuming tables with frequent updates and deletes. Under the hood, this procedure also helps to improve the performance of other CRUD operations performed on those tables. In this tutorial we will explain how to optimize SELECT queries with WHERE clauses using indexes in PostgreSQL tables.
1. Introducing indexes
The best way to introduce the concept and the use of indexes in a database is using a book analogy. If you buy a new book for a college class, you will most likely start by looking at the index at the end of the book for a particular topic. There is no doubt that this would be a much faster way to find the information that you need than thumbing through the book from the beginning.
Likewise, in the context of databases, an index is an actual structure that references the information found in a given table.

2. Examples
Let’s return to the book analogy for a moment and use the World_db database to illustrate the need for indexes. Let’s modify a little the query that we used as an introductory example in the first article of this series:
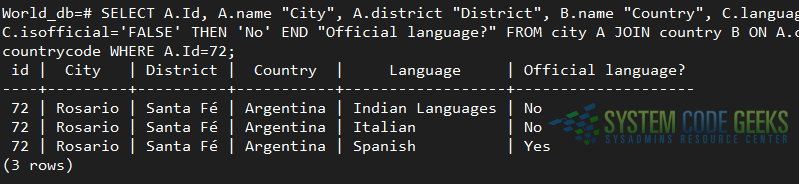
SELECT A.Id, A.name "City", A.district "District", B.name "Country", C.language "Language", CASE WHEN C.isofficial='TRUE' THEN 'Yes' WHEN C.isofficial='FALSE' THEN 'No' END "Official language?" FROM city A JOIN country B ON A.countrycode=B.code JOIN countrylanguage C ON A.countrycode=C.countrycode WHERE A.Id=72;
The above query will return all records where the Id column in the city table is 72. Since we are performing a JOIN operation with other tables it is to be expected that we will get more than one result. In this case, we got 3 different records based on the different languages associated with this city, as you can see in Fig. 1:
If SELECT operations like the above query are performed frequently searching by city.Id, it makes sense to create an index on that column in order to improve the overall performance. Before we do that, let’s do an EXPLAIN ANALYZE on this query by prepending this operation to the query itself. This will perform the query and indicate the execution time (see details highlighted in yellow in Fig. 2):
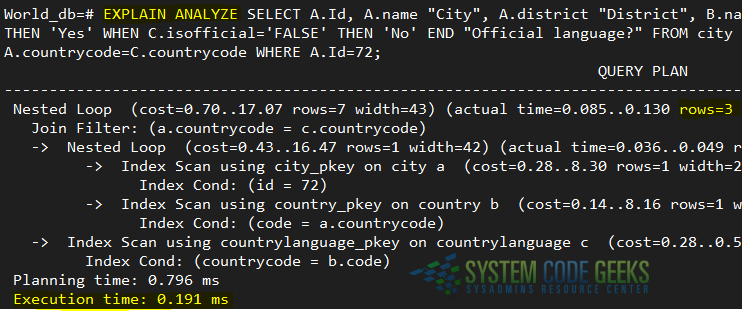
As you can see, EXPLAIN ANALYZE says 3 rows were returned and gives us information about each step of our query. The execution time was 0.191 ms.
Let’s now create the index on the city.Id column as follows. Please note that your indexes must ideally have a descriptive name (cityId_idx in this case, which fairly indicates that it is associated with the city.Id column):
CREATE INDEX cityId_idx ON city(Id);
Then repeat the EXPLAIN ANALYZE plus the query. Results are shown in Fig. 3:
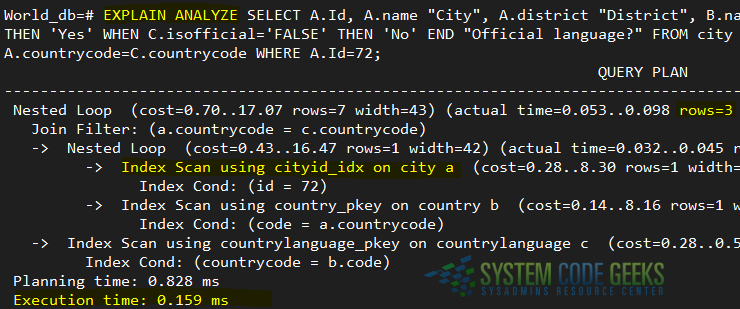
We can see that the use of the newly-created index was able to reduce the execution time by ~17% (0.159 ms compared to 0.191 ms).
On top of that, please refer to the figures in Fig. 4 that correspond to each query:

While the number of rows returned by each query was the same, the numbers inside parentheses show a performance increase. The first number (0.085 in the first case and 0.053 in the second) represents the estimated start-up time of the associated query step whereas the second number (0.130 and 0.098) indicates the actual execution time of such step.
3. Unique indexes
There is a special type of index called unique. When it is used, it guarantees that the associated table will not have more than one row with the same value and thus will helps us maintain data integrity and improve performance. Instead of a regular index, we could have created an unique index in the city.Id column above as follows:
CREATE UNIQUE INDEX cityId_idx ON city(Id);
You can also delete existing indexes in PostgreSQL as follows:
DROP INDEX cityId_idx;
Fairly easy, isn’t it?
In this sense, an unique index will prevent a record with the same Id to be inserted into the table if no previous constraint (such as an primary key) exists on that column.
4. Multicolumn indexes
If you are likely to use more than one column in a SELECT query with a WHERE clause frequently, you may considering using a multicolumn index on them. The syntax is similar to the case of a single index:
CREATE INDEX index ON table (column1, column2);
where column1 and column2 are the columns where the index will be created. Feel free to add more columns if needed.
5. Summary
In this article we have discussed the need for indexes to improve performance on SELECT queries that use WHERE clauses. If you keep in mind the book analogy presented at the beginning, you will remember the fundamental concept behind using indexes.

Really Useful article, it sound good to understand the indexing.
thanks a lot….